
May 2026 Ultra Growth Newsletter 2.0 Part II

We FINALLY GOT The Correction WE NEEDED To REbuild Age of Inference AI Positions
It's a WILD May -- and we just got a MUCH NEEDED textbook "risk-off" sector rotation, but with a highly specific trigger: the reality check of Q1 earnings season colliding with highly speculative "melt-up" valuations in many sectors. As he should, Mr. Market is aggressively pulling capital out of pre-revenue, high-beta "narrative" stocks and shifting back into safer havens or proven cash-flow giants.
Which is great for us, investing in the global UNSTOPPABLE 5 YEAR $5.7 trillion AI infrastructure build-out--with PROVEN rising cash flows in most cases
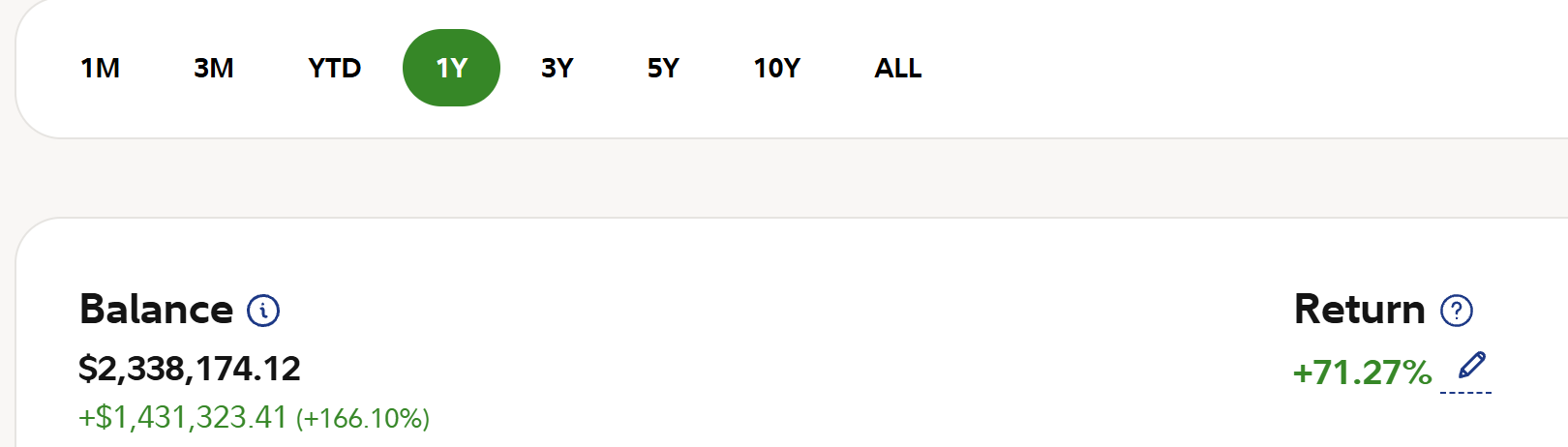
As both our subscribers and a growing number of wealth management clients (minimum account is $500,000)--thanks to the last 4 AI Stock Meltdowns--the average annual TR Wealth Management Ultra Growth portfolio value growth 2024-2025 has been 84.5% per year, and May 25 2026 is already at 71%!
BTW some of these positions are still buyable today (if you want to, which ones, see below and get a paid subscription if you are not currently a paid subscriber"
My point? — We have seen this show before — news headlines like "DeepSeek crushing US AI platforms" — so let's use Micron as the poster child for the AI Data Center trade--and now what we have come to call "The Age of Inferential AI." Since the start of the AI boom in early 2023, several "fear events" have triggered sharp sell-offs in chipmakers like Micron (MU). These events typically follow a pattern: a sudden panic over regulation, competition, or demand, followed by a robust recovery as long-term AI infrastructure needs and sold-out HBM HDD Hard Drive and NAND memory demand through 2028 (plus custom TPUs outweigh the short-term noise.
Below are the major AI trade fears events and Micron's performance six months after each since 2025:
1. The DeepSeek "Cost Efficiency" Shock
The Event (January 27, 2025): The release of China's DeepSeek-V3 sparked fears that advanced AI could be built for a fraction of the cost ($6 million vs. billions), potentially reducing the need for massive hardware spend.
The Sell-off: Micron and other chip stocks fell sharply on concerns of "hardware deflation."
Six Months Later: By July 2025, the fear had largely been debunked, as it became clear that while models were efficient, the sheer volume of AI inference was skyrocketing, keeping memory demand high. Micron's stock reached new highs during this period as HBM (High Bandwidth Memory) capacity remained sold-out (and Sandisk too for its NAND memory)
2. The US-China Export Restriction Panic
The Event (October 2023): The US Department of Commerce tightened export controls on advanced AI chips (like NVIDIA’s H100, which require a lot of MBM and NAND for AI Inference) to China.
The Sell-off: Investors feared a massive loss in the Chinese market for memory and logic chips. Micron dropped toward its 52-week lows in the $60s.
Six Months Later (April 2024): MU was trading near $120, an increase of nearly 90%. The rally was driven by the realization that US hyperscalers (Meta, Microsoft, Amazon) were more than making up for any lost Chinese demand.
3. The ASML "Earnings Warning."
The Event (April 15, 2026): ASML reported a slight miss on Q2 guidance, leading to fears that the "peak" of the AI buildout had arrived.
The Sell-off: MU fell roughly11% alongside a broader semiconductor retreat amid investor concerns over overcapacity.
Current Status: Within weeks, the narrative shifted. By May 2026, analysts at DA Davidson and TD Cowen raised targets to $660–$1,000, noting that memory shortages ("RAMmageddon") were actually worsening.
And now yesterday, a federal Korean politician posts on FACEBOOK his idea to use some of the windfall corporate income taxes paid by Korean HBM memory chip foundries for the good of the less fortunate Koreans--NOT A Memory Maker TAX RATE HIKE!--just an allocation of the "windfall corporate income taxes" being paid by Korean HBM memory foundries like Samsung and Himax by the South Korean Federal government.
He used Norway as a comparison, which shares hundreds of billions of dollars in oil and natural gas royalties to support free education and healthcare. His idea is simply that South Korea should EXPLORE a “people’s dividend” using AI-driven corporate tax revenue, as booming profits at Samsung and SK Hynix fuel concerns about inequality.
However, when the global hedge fund algorithms "read" this Facebook post--all they "read" was "South Korea RAISES taxes AI hardware sales revenue" and hit the sell buttons around the world in an HBM/NAND/HDD memory selling orgy.
And then today in South Korea . . .
Samsung Electronics Labor Strike As of mid-May 2026, Samsung is on the brink of its most disruptive labor action in history.
Imminent Strike: The National Samsung Electronics Union (NSEU) has announced an 18-day general strike beginning on May 21, 2026. This follows the collapse of government-mediated negotiations on Wednesday, May 13.
Failed Outreach: In a rare move today, May 15, Samsung’s top executives, including semiconductor head Jun Young-hyun, visited union leaders in Pyeongtaek to revive talks. However, the union remains firm in its demands for permanent changes to bonus calculation rather than one-time payments.
Financial Impact: Analysts estimate the strike could cost Samsung over $700 million per day, with total projected damages reaching up to $20 billion.
PS: SK Hynix — the OTHER South Korean HBM memory-making giant —has NO labor problems because, in September 2025, they agreed to allocate 10% of their operating profit to their staff for the NEXT 10 YEARS! And of course, the Samsung staff want the same deal!
Key Point: So US-based and owned Micron and Sandisk stocks should be UP TODAY, and for as long as the amount of Samsung HBM chips is ZERO, right
But Micron stock is down today 5.5% with an 80/20 split between HBM and NAND memory production— while NAND memory maker Sandisk is UP 2%??
HERE is why we LOVE FALSE "AI Trade is Over" Sell Offs!
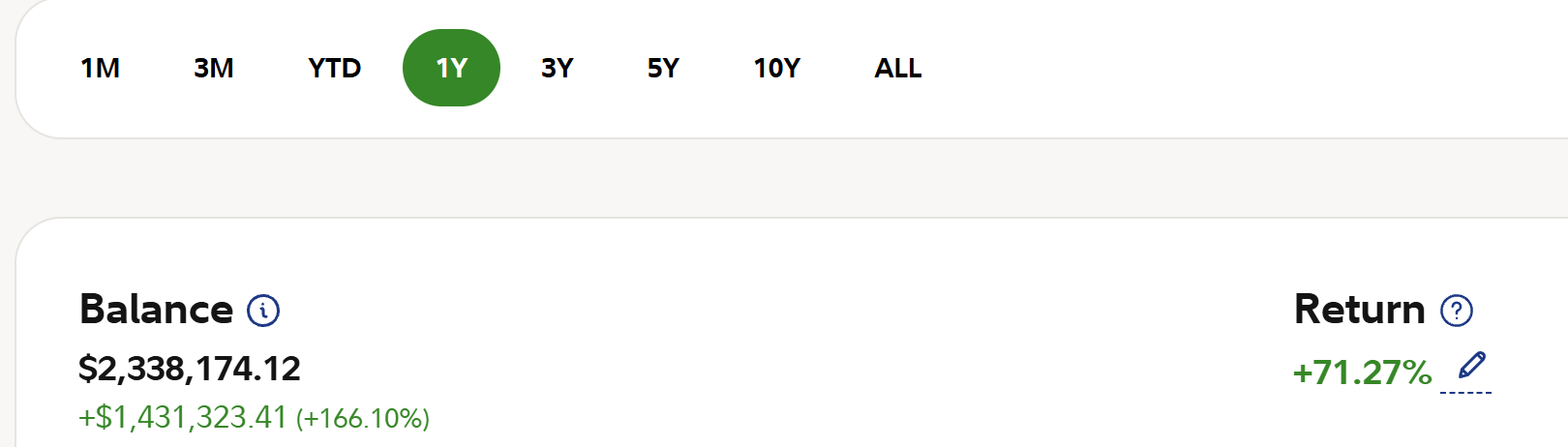
As both our subscribers and a growing number of wealth management clients (minimum account is $500,000)--thanks to the last 4 AI Stock Meltdowns--the average annual TR Wealth Management Ultra Growth portfolio value growth 2024-2025 has been 84.5% per year, and May 25 2026 is already at 71%!
NOTE: IF you are interested in opening a TR Ultra Growth Wealth Management account ($500,000 minimum--IRAs fine!), we have openings for just 10 MORE clients-- contact Marjorie Sutherland-Smith at msmith6116@gmailcom or text 301 520-9610
Back to Why We Love Major "AI Is a BUBBLE" BS Fear Dips
China Export Ban Oct 2023
Geopolitical Risk
Bounced back +90% (approx. $120)
NVIDIA Margins Fear
April 2024
"AI Bubble" talk
Bounced +40% Higher (reached $150+)
DeepSeek Launch
Jan 2025 Cost Disruption AI stocks down 30%+
Bounded Back +250% Higher (multi-month rally) UNTIL Yesterday!
But no fear--today we introduce one of the MANY NEW features of our TR Ultra Growth Equity Research service 2.0 --and get your portfolio ready for the NEXT 50% bounce back in the world's best stocks you must own to build wealth in the Age of Inference AI Revolution 2.0.
But first — my bet is for you to really make big $$ in the Age of AI Inference 2.0 Revolution, you REALLY need a quick primer on the key difference between building Large Language Models (aka LLMs) and GETTING amazing value in your professional work life from Claude, Gemini, ChatGPT, or Perplexity "Chatbots" that I now call $ 100-a-month PhD research Assistants.
How We Are Building REAL Wealth Investing in the Age of AI Inference Revolution 2.0 2026-2031
First off, you and I need to understand how A) strategically important Inferential AI capacity and dispersion are to every modern country and economy in the world, and B) what the global construction and rollout of Inferential AI+ Agentic AI technology 2.0 is REALLY conservatively forecast to cost the global economy 2026-2030.
As of May 13, 2026, the global landscape for AI infrastructure has shifted rapidly, and as of May 2026, the estimates for inferential capacity and general AI development 2026-2031 have reached astronomical levels. The good news for your wealth is that the VALUATIONS of the ENTIRE building blocks that drive Inferential AI Revolution 2.0 are getting RE-RATED because MANY of the key enabling technologies involved in Inferential AI 2.0 are SOLD OUT till 2027 and many to 2028!
The very latest estimated global cost of the build-out of the Age of Inference AI revolution is as follows:
The "HISTORIC $$Global AI Infrastructure Spend Numbers" for 2026-2031
Let me be clear: the total global capital expenditure (CapEx) for AI infrastructure is no longer measured in billions, but is rapidly approaching the $TRILLION ANNUAL mark.
Category 2026 Estimate 2030-2031 Projection Annual Global AI CapEx $765 Billion $1.6 Trillion Top 5 Tech Giants (Combined) $660 – $690 Billion — Cumulative Global Investment $5.2 – $7.6 Trillion Global AI Infrastructure Market $142.8 Billion $947 Billion (by 2035)
Breakdown of Development Costs
The "cost" of development isn't, of course, just about the chips (GPUs/TPUs/APUs/CPUs); it's about the entire physical and digital stack required to run models in answer production mode (aka AI "inference").
Hyperscaler Dominance: The "Big Five" (Amazon, Alphabet, Microsoft, Meta, and Oracle) are the primary drivers. Amazon alone is projected to spend $200 billion in 2026, followed closely by Alphabet at $185 billion.
The Shift to Inference: While 2023–2025 was defined by "Training" costs, Inference AI will account for 55%-80% of all enterprise spending in 2026 and beyond
The Infrastructure "Tax": Roughly 25% ($1.3 trillion) of the total long-term investment is being funneled into metered and onsite power, cooling (liquid immersion), and electrical grid upgrades, which have become the primary bottlenecks.
Key Cost Drivers in 2026
Hardware Hardware (51.7% of spend): Includes the massive 2026 rollout of VERA RUBIN (B200), built around a new "superchip architecture " that started production in H2 2026, and custom ASICs (TPUs, APUs, Trainium, Inferentia).
Power & Grid Upgrades: Data center power demand is projected to rise 165% by 2030, requiring roughly $720 billion in global grid upgrades just to keep the lights on.
Sovereign AI: Governments (EU, Saudi Arabia, Japan, India) have committed over $84 billion to build nationalized AI infrastructure to ensure data sovereignty.
Note on "Inference Economics": The marginal cost of inference—the cost to generate a single response—has become the new "KPI" for the industry. Companies are currently spending approximately $0.95 to $3.18 per million tokens (depending on the GPU tier) to maintain high-reasoning model capacity at scale.
In the world of AI, a token is the fundamental unit of information that an LLM processes. Think of it as the "atomic" level of language for a computer.
What is a Token?
A token is not necessarily a single word. Depending on the model's tokenizer, a token can be:
• A whole word (e.g., "apple")
• A part of a word (e.g., "ing" or "pre")
• A single character or punctuation mark.
As a rule of thumb, 1,000 tokens are roughly equivalent to 750 words.
The Role of Tokens in Inferential AI
In the Inference phase (when the AI is generating a response for you), tokens serve three critical roles:
1. The "Currency" of Logic: During inference, the AI doesn't "think" in concepts; it calculates the statistical probability of which token should come next based on the tokens that came before it.
2. Memory Management (Context Window): Every token you type into a prompt and every token the AI generates back takes up space in the Context Window. Once you hit the token limit, the AI "forgets" the earliest parts of the conversation to make room for new tokens.
3. Cost and Speed (The "KPI"): As noted above, the "Marginal Cost of Inference" is measured in tokens (e.g., spending $0.95 to $3.18 per million tokens). Because each token requires a trip through the high-speed memory (HBM), more tokens mean more compute time and higher costs.
Simple Analogy: If the LLM is a chef, tokens are the pre-chopped ingredients. The chef (Inference engine) doesn't have time to grow the vegetables; they just grab the "tokens" and arrange them into a finished meal (your report).
1. The Total Breakdown of the $5.2 Trillion AI Investment 2026-2031
According to the latest 2026 industry outlooks, total spending is segmented into three primary categories:
Technology & IT Equipment ($3.1 Trillion / 60%): Spend on AI chips (GPUs/TPUs/APUs), high-performance networking, and advanced storage. This reflects the "fit-out" phase of new builds.
Energy & Power Infrastructure ($1.3 Trillion / 25%): Covers the "Energizers"—on-site power generation (turbines, fuel cells), power transmission, cooling systems, and electrical transformers.
Real Estate & Core Construction ($800 Billion / 15%): Land acquisition, physical building materials, and site development for greenfield projects.
2. On-Site Power: The New "Gating Factor."
With global data center occupancy at a record 97%, the primary bottleneck is no longer land or capital, but time-to-power.
GE Vernova (Gas Turbines): Data center orders for GE Vernova reached $2.4 billion in Q1 2026 alone, surpassing its total orders for all of 2025. Their gas turbines are being deployed as bridge power for gigawatt-scale campuses that cannot wait for grid connections. They are sold out till 2028.
Bloom Energy (Fuel Cells): Bloom Energy reports that 73% of operators are now embedding on-site power into their long-term strategies. Their solid-oxide fuel cell servers are increasingly used for "behind-the-meter" generation to provide high-density power for AI racks.
Capacity Surge: Approximately 100 GW of new data center capacity is expected to be added between 2026 and 2030, doubling global capacity. For context, JLL Research estimates that 100 GW of new supply requires roughly $3 trillion in direct investment, excluding high-end IT fit-outs.
3. Regional and Strategic Shifts
Hyperscale Dominance: The "Big 4" (Amazon, Google, Meta, Microsoft) are projected to invest over $400 billion in 2026 alone.
Inference vs. Training: A major pivot is expected in 2027, when Inference workloads are projected to overtake training as the primary driver of data center demand, requiring different power and cooling architectures.
Cost of Build: Construction costs are rising at a 7% CAGR, with JLL forecasting average costs to hit $11.3 million per megawatt (MW) by late 2026.
Summary Table: Age of Inference AI Investment Forecast (2026-2030)
Category Spend Estimate Key Beneficiaries IT Hardware $3.1 Trillion NVIDIA, AMD, Custom TPU Manufacturers Power Systems $1.3 Trillion GE Vernova (Turbines), Bloom Energy (Fuel Cells), Micron (HBM) Construction $800 Billion Equinix, Digital Realty, Specialized EPC Firms Total $5.2 Trillion
The Age of Inference AI Revolution 2.0
This year, with the logarithmic 800X explosion of Claude AI users and $90 BILLION revenue forecast in 2027 (and if you are in white-collar knowledge work and do NOT use Claude AI every day--your job is in serious jeopardy), we have hit a crucial pivot point in the AI market: the shift from the "Build" phase to the "Value" aka mass productivity revolution phase.
Here is the breakdown of the technical differences between Training LLMs and AI Inference in simple terms.
1. The Goal: Building the Brain vs. Using the Brain
The fundamental difference is what the computer is actually doing with its "thinking" power.
Building LLMs (Training): This is the "Education" phase. Huge supercomputers are fed trillions of words from the internet to teach the model how language, logic, and facts work. It is incredibly expensive and happens once every few months/years.
Inference Chatbots (Usage): This is the "Work" phase. When you ask Claude or ChatGPT to write a report, the model is already built. It is simply "inferring" (predicting) the next best word based on your prompt. It’s like a PhD student who has already graduated and is now just answering your questions.
2. The Technology: What’s Under the Hood?
The hardware requirements for these two tasks are shifting, which is why stocks like Micron are reacting to news about "Inference".
Feature Building LLMs (Training) AI Inference (Usage) Primary Hardware Massive clusters of NVIDIA GPUs (H100/H200). A mix of GPUs and specialized CPUs, TPUs, & APUs Inference Chips. Memory Need High-speed data throughput to "learn" fast. Massive HBM (High Bandwidth Memory) to "recall" facts instantly. Computing Style Brute Force: High power, high heat, massive electricity. Efficiency: Needs to be fast and cheap enough to run millions of chats per second. Data Flow Feeding the model new info. Processing your info through the existing model.
In the context of our "Inference Revolution" theme, TPUs and APUs represent the move away from "one-size-fits-all" hardware toward specialized efficiency.
If the GPU is a high-performance race car, these two chips are the specialized electric delivery vans and hybrid engines of the AI world.
1. TPUs (Tensor Processing Units)
The Specialist: Developed by Google, the TPU is an "ASIC" (Application-Specific Integrated Circuit). Unlike a GPU, which was originally designed for graphics, the TPU was built from the ground up for one thing: Tensor Math (the specific math AI uses).
Role in Inference: TPUs are the kings of throughput. While a GPU might be faster at a single complex task, a TPU is designed to handle millions of tiny, simultaneous inference requests (such as Google search or Google Translate queries) with very little power.
The "Inference" Benefit: Because they are so specialized, they can run models with much higher energy efficiency. In your newsletter, you can frame this as the "Cost Killer"—TPUs allow big companies to provide AI services without their electricity bills bankrupting them.
2. APUs (Accelerated Processing Units)
The Hybrid: An APU (primarily an AMD term) is a single chip that combines the CPU (the manager) and the GPU (the muscle) into one unit.
Role in Inference: This is the technology behind "On-Device AI." Instead of sending your report data to a massive data center (Cloud Inference), an APU allows your laptop or phone to do the work locally.
The "Inference" Benefit: By putting the processor and the graphics cores on the same piece of silicon, data doesn't have to travel far. This eliminates the "bottleneck" between the brain and the memory. For your readers, this means Privacy and Speed—the AI can summarize a sensitive corporate report right on the user's desktop without it ever hitting the internet.
Technology Best For... Why it Matters for Inference TPU Scale: Massive Cloud Inference Lowest cost per "chat" or "query" for providers like Google. APU Local: AI PCs and Laptops
The Investor Angle: Beyond the NVIDIA Monopoly
The rise of TPUs and APUs is the "NVIDIA-Killer" narrative is silly (lol at $7 TRILLION market cap, NVIDIA, I guarantee, will SWALLOW the best Inferential AI tech chip companies).
Custom Silicon (TPUs): Companies like Google, Amazon (Inferentia), and Meta are building their own TPUs to stop paying the "NVIDIA Tax."
The APU Opportunity: AMD is using APU technology to win the "AI PC" war. As inference moves from the cloud to our laptops, the demand for chips capable of running "good enough" AI without a $2,000 GPU is skyrocketing.
Simple Analogy: > If a GPU is a massive power plant, a TPU is a highly efficient solar farm designed for a specific city, and an APU is the rechargeable battery inside your house that keeps your lights on locally.
4. Why This All Matters for Research and Writing
When you use a chatbot for professional reports, the "Inference" technology is doing something specific that training doesn't:
Context Windows: Inference technology allows the "PhD Assistant" to hold 100+ pages of your specific data in its "short-term memory" while it writes. This doesn't change the base LLM; it just uses the Inference engine to process your specific report.
Speed vs. Accuracy: Training focuses on deep logic. Inference technology is being optimized for Latency (how fast the text appears) and Throughput (how many people can use it at once without the system crashing).
5. The "Inference Revolution" Investor Angle
As we noted in the term "RAMmageddon," the shift toward Inference is a massive tailwind for memory companies like Micron (MU), Sandisk (SNDK), Samsung, and Hynix (which we own in the $KURO ETF that we sold but will buy back with strike settlment!).
While Training requires a lot of compute, Inference requires a staggering amount of Memory (DRAM/HBM). Think about this: EVERY time a chatbot "thinks" of a word, it has to move that data through memory. As we move from building models to actually using them for trillions of hours of professional work, the demand for the chip's "memory" part becomes more important than its "processing" part.
Simple Analogy: > Training is like building a massive library and stocking the shelves (expensive and slow
Inference is like a librarian sprinting through those aisles to find the exact book you need in half a second (requires speed and high-tech sneakers).
In the AI Inference process—which is the "work" phase where the model answers your questions—NAND (Flash Memory) and Hard Drives (HDD) serve as the "Long-Term Storage" or the "Warehouse" of the system.
While HBM (High Bandwidth Memory) is the "sprinting librarian" finding immediate answers, NAND and HDDs provide the foundation that enables AI to operate and handle massive datasets.
1. Storing the "Brain" (The Weights)
A Large Language Model (LLM) is essentially a massive file consisting of billions of "weights" (numerical values that represent knowledge).
The Role: When an AI service (like ChatGPT or Claude) starts up, those massive model files are stored on NAND Flash (SSDs).
The Tech: Hard drives are generally too slow for this today. High-speed NVMe SSDs (using NAND) are required to "load" the model into the active memory (GPU RAM/HBM) so it can begin processing your request.
2. The "Knowledge Base" (RAG and Big Data)
When you ask an AI to write a report based on 500 PDF documents you uploaded, it uses a process called Retrieval-Augmented Generation (RAG).
NAND/SSD Role: Your 500 documents aren't stored in the AI's "brain." They are stored on NAND storage. When you ask a question, the system quickly "retrieves" the relevant snippets from the SSD and feeds them into the processor.
HDD Role: Hard drives are the "Cold Storage." If a company has petabytes of historical research data that the AI might need one day but doesn't need this second, it stays on cheap, high-capacity Hard Drives to save money.
3. Key Differences in the Inference Cycle
Technology Role in Inference Speed Simple Analogy HBM / DRAM Active "Thinking" Ultra-Fast The desk you are currently working at. NAND (SSD) Active Retrieval Fast The filing cabinet right next to your desk. Hard Drive (HDD) Mass Archiving
Final Point
There’s supply and demand for AI computing power, and there’s supply and demand for AI itself. The two should be linked, but that hasn’t always appeared to be the case. In the past few months, however, the two sides of the AI equation have lined up nicely . . and THAT is a HUGE Deal for investment returns for you and me and my wealth management clients from the Age of Inferential AI.
To put it another way, the long-term case for AI demand has strengthened significantly, which justifies the massive investment in AI data centers. This shift to the Age of AI Inference 2.0 WIL unlock huge funding for the infrastructure behind AI, helping developers meet the surging demand for computing power for the major ChatBot providers Anthropic/OpenAI/Perplexity/Microsoft/Google (their Gemini AI ChatBot is 10X better than just a year ago) around the WORLD (as EVERY modern country in the world HAS TO KEEP UP with USA/China/Europe in Inference/Agentic AI capabilities.
The shift to Inference/Agentic AI justifies the HUGE fundraising at OpenAI et sl and increases the likelihood that it and Anthropic will have epic initial public offerings in the next 12 months. It also should give investors confidence that higher spending on computing power by Meta Platforms and others is warranted.
PS--the annual revenue runway/ramp for Anthropic and its Claude AI is on track to $70 BILLION by 2028--the company, as the WSJ reported this week, had a $30 billion run-rate this April for 2027--that was up from $9 billion at the end of 2025--and an 80-fold growth in annualized revenue and usage in the first quarter of 2026!
In short... Anthropics 80-fold growth in usage means they have to get 80-fold MORE AI DATA COMPUTING CAPACITY in 2026--you getting my drift here?
In NO OTHER INDUSTRY other than World War II, going from a few hundred planes and bombers to 800,000 between 1939 and 1945, has a company grown 80X--but this is 80X in just 90 days--mindboggling!
LOL, CEO Dario Amodei said on the conference call I was on that the company planned 10x growth in Q1 2026 — not 80X!
And the 2027 annualized growth rate forecast?
2027 Projections: Internal projections shared by The Information suggest revenue will reach $34.5 billion by 2027. Some analysts speculate the company could even rival Google's revenue levels by late 2026 if current trajectories hold.
Long-term Outlook: The company anticipates reaching up to $70 billion in revenue and $17 billion in cash flow by 2028. And this company was pre-revenue until early 2023!
My optimism for the unimaginable growth of commercial Inferential/Agentic AI ALSO stems from the emergence of big-money backers seeking to accelerate business adoption of AI. Last week, Stephanie Palazzolo at The Information scooped news of a potential joint venture involving Anthropic and private equity firms Blackstone and Hellman & Friedman. OpenAI appears to be doing the same thing with private equity firms TPG, Brookfield Asset Management, and Bain Capital.
Those reports were quickly followed by news that Jeff Bezos is raising $100 billion to buy up manufacturing companies and use AI to help them automate. If Bezos can raise the money, the fund would be one of the biggest ever.
Key Point: All of $trillions in inferential AI capacity DID NOT happen in a vacuum.
AI models, especially Anthropic's newest versions of Claude, coupled with OpenClaw—software for creating AI agents—have made AI’s capabilities incredibly clear and are being massively adopted worldwide (PS I use ClaudeAI/OpenClaw and Gemini EVERY DAY).
What’s also become clear is that AI agents —and AI Inference's insane use case demand for $Trillions in more computing power—are NOT likely to slow down in the next 5 years — they're actually speeding up!
What I am really saying here is that ultimately, what matters for you and me as investors in the Age of Inference AI is the DEMAND GROWTH RATE for Inference & Agentic AI IS UNSTOPPABLE in the same way getting a PC on every work desk/home/school etc was with the birth of the PC--the Internet--and the smart phone.
The private equity joint ventures aimed at accelerating AI adoption in millions of businesses will certainly boost demand across almost every industry.
Final Point: Think about this: just these 10 US-based private equity firms own more than 2,000 companies that generate roughly $2 trillion in revenue spread across nearly every industry. Let me go back to my remark about how Claude AI is a $100-a-month research assistant for me.
Well, I just checked — my Claude AI Chatbot — I nicknamed him "Claudius Maximus" — the total token cost of his help in putting together this research report and writing the 15 other Inferential AI research reports on our website, www.transformityresearch.com, was $2.56.
For the NON-PAID folks on this email list --Here's a FREE LINK (for a limited time!) to our 13 (soon to be 15) deep research into the entire Age of Inferential + Agentic AI ecosystems of public (and private ones on an IPO path):
https://www.transformityresearch.com/reports
Now consider this reality: The day rate for an editorial assistant/consultant with the deep AI expertise that Claudius Maximus has access to is $800 – $1,500 Mid-Level AI Consultant per day
Now extrapolate that 400X+ LOWER cost of knowledge labo